
Nexenta Blog
Is 2016 the year of the software-defined data center? Part 2
20 May 2016 by Nexenta
In the last blog we determined that the world has changed since the early 2000s and that x86 has won the server war, now giving you a chance to have vendors compete for you. But that’s only part of the data center — we still have to look at the rest of the infrastructure.
Networks that can shift and deliver at the same time
In the past, if you wanted to have the fastest network infrastructure you had to buy from one or two specific vendors. In reality, they still have a huge share of the networking market, but we’ve seen a transition in recent years.
That being said, it is not just about the software layer — with scale-out systems, the network has become critical for more than just inter-rack and inter-data center connectivity, and critical for processing power and speed as well. The move from 1GB to 10GB to 40GB, and even up to 100GB, is allowing for larger amounts of traffic than ever before to move around the globe. This is all done at a scale that can give even the smallest enterprise access to faster connectivity, but it still comes at a cost.
While 10GB is starting to become commonplace, it is still a much more expensive option than 1GB and not something that has trickled down to the end user yet. The true question is, does it need to? If the data center is driven by commodity hardware that is governed by software and all the compute happens there, do we really need to be faster at the endpoint? To answer that, we will have to wait and see.
The brains behind the brawn
The No. 1 buzzword of the last few years has been “software-defined,” and rings true for the transition we have seen in the data center over the last 10 years. The first step is compute, with virtualization taking its place as a stalwart to provide the processing power needed on commodity hardware.
The next two parts that need to move to the software-defined space to allow for a commodity-driven data center are storage and networking. Some would argue that we are already there, with executives from major storage vendors making statements as early as 2010 that “we all run on commodity hardware.”
In reality, you are normally limited to the hardware that a vendor chooses. Moving into a software-defined model means we have choice in vendors and can truly liberate the storage needs from the hardware vendor’s grasp. The growth of open source-based solutions has helped this along the way, and we will see if 2016 is the year we take the leap to make software-defined the norm.
Networking, on the other hand, is the last step forward. You cannot buy a blank switch off the shelf and just layer on the software of your choosing and make it work at the speed and capacity that you desire, but we are starting to see a transition toward this. The combination of software-defined solutions is what gives companies the agility to transition to the enterprises of tomorrow, providing the ability to custom-fit a solution into the business instead of the other way around. It appears that software-defined is more than just a buzzword.
So is it the year?
My gut says the commodity-based data center is not ready to go mainstream, but for intrepid companies willing to source the right gear, it may be. We have seen so many changes in the data center since the ’90s and the early 2000s that I have to believe the pace of change will continue.
Before we cross into 2020, the data center will be in the domain of the business again, not the vendors. That will be the commodity data center that anyone who has managed a data center in the last 20 years has been dreaming about.
Three Dimensions of Storage Sizing & Design – Part 1: Overview
16 May 2016 by Nexenta
By Edwin Weijdema, Sales Engineer Benelux & Nordics
Why do we build ICT infrastructures? What is the most important part in those infrastructures? It is Data! With the digital era we need to store bits of information, or so called data, so we can process, interpreter, organize or present that as information by providing context and adding value to the available data. By giving meaning and creating context around data we get useful information. We use data carriers to protect the precious data against loss and alteration. Exchanging floppies/tapes with each other was not that efficient and fast. So storage systems came into play, to make it easier to use, protect and manage data.
Networks and especially the internet connects more and more data and people. Designing and sizing storage systems that hold and protect our data can be a bit of a challenge, because there are several different dimensions you should take into consideration while designing and sizing your storage system(s). In the Three Dimensions of Storage Sizing & Design blog series we will dive deeper into the different dimensions around storage sizing and design.
Use
 In this digital era we are using and creating more data than ever before. To put this into perspective, the last two years we created more data than all years before combined! Social media, mobile devices and smart devices combined in internet of things (IoT) accelerate the creation of data tremendous. We use applications to work with different kind of data sources and to help us streamline these workloads. We create valuable information with the available data by adding context to it. A few examples of data we use, store and manage are: documents, photos, movies, applications and with the uprise of virtualization and especially the Software Defined Data Center (SDDC) also complete infrastructures in code as a backend for the cloud. In the last two years we created more data worldwide, than all digital years before!
In this digital era we are using and creating more data than ever before. To put this into perspective, the last two years we created more data than all years before combined! Social media, mobile devices and smart devices combined in internet of things (IoT) accelerate the creation of data tremendous. We use applications to work with different kind of data sources and to help us streamline these workloads. We create valuable information with the available data by adding context to it. A few examples of data we use, store and manage are: documents, photos, movies, applications and with the uprise of virtualization and especially the Software Defined Data Center (SDDC) also complete infrastructures in code as a backend for the cloud. In the last two years we created more data worldwide, than all digital years before!
Workloads
To make it easier and faster to work with data, applications have been created. Today we use, protect and manage a lot of different kind of workloads that run on our storage systems. The amount of work that is expected to be done in a specific amount of time, has several characteristics that defines the workload type.
- Speed– measured in IOPS (Input/Output Per Second), defines the IOs per second. Read and/or Write IOs can be of different patterns (for example, sequential and random). The higher the IOPS the better the performance.
- Throughput– measured in MB/s, defines data transfer rate also often called bandwidth. The higher the throughput, the more data that can be processed per second.
- Response– measured in time like ns/us/ms latency, defines the amount of time the IO needs to complete. The lower the latency the faster a system/application/data responds, the more fluid it looks to the user. There are many latency measurements that can be taken throughout the whole data path.
It is very depended on the type of workload which characteristic is the most important metric. For example stock trading is very latency dependent, while a backup workload needs throughput to fit within a back-up window. You can size and design the needed storage system if the workloads are known that will be using the storage system(s). Knowing what will use the storage is the first dimension for sizing and designing storage systems correctly.
Protect
A key factor to use storage systems for, is to protect the data we have. We must know the level of insurance the organization and users need/are willing to pay for, so we can design the storage system accordingly. We need to know the required usable capacity combined with the level of redundancy so we can calculate the total amount of capacity needed in the storage system. Always ask yourself do you want to protect against the loss of one system, entire data centers or even across geographic regions, so you can meet the availability requirements.
- Capacity– measured in GB/TB/PB or GiB/TiB/PiB. The amount of usable data we need to store on the storage and protect.
- Redundancy– measured in number of copies of the data or meta data which can rebuild the data to original. e.g. measures like for instance parity, mirroring, multiple objects.
- Availability– measured in RTO and RPO. The maximum amount of data we may lose called the Recovery Point Objective (RPO) and the maximum amount of time it takes to restore service levels Recovery Time Objective (RTO).
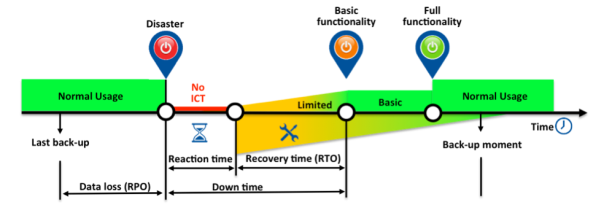
Knowing how much data we must protect, against defined protection/service levels (SLA’s), gives us the second dimension for sizing and designing the storage system correctly.
Manage
Working with storage systems and designing them takes some sort of future insight or like some colleagues like to call it: a magic whiteboard. How is the organization running, where is it heading towards and what are the business goals to accomplish. Are business goals changing rapidly or will it be stable for the next foreseeable future? That are just a few examples of questions you should ask. Also a very important metric is the available budget. Budgets aren’t limitless so designing a superior system that is priceless will not work!
- Budget– an estimate of income and expenditure for a set period of time. So whats the amount of money that can be spend on the total solution and if departments are charged whats the expected income and how is that calculate, e.g. price per GB/IOPS/MB, price per protection level (SLA’s) or a mix of several. Also specific storage efficiencies features, that reduce the amount of data, should be taken into account.
- Limitations– know the limitations of the storage system you are sizing and designing. Every storage system has a high-watermark where performance gets impacted if the storage system fills up beyond that point.
- Expectations– How flexible should the system be and how far should it scale?
Its all about balancing cost and requirements and managing expectations to get the best possible solution, within the limitations of the storage system and/or organization. Managing the surroundings of the proposed storage solution gives us the third and final dimension for sizing and designing storage systems.
Overview
Sizing and designing storage systems is, and will always be, a balancing act about managing expectations, limitations and available money to get the best possible solution. So the proposed workloads will run with the correct speed, throughput and responsiveness while full-filling the defined availability requirements. With the uprise of clouds and Infrastructures as a Service (IaaS) vendors, organizations just tend to buy a service. Even if that’s the case it helps tremendous selecting the correct service when you understand how your data is used, against which protection levels so you can manage that accordingly.
To get the best bang for your buck its helps to understand how to determine the three dimensions correctly, so you can size & design the best solution possible. In the next parts of this blog series we will dive deeper into the three dimensions of storage sizing & design: Use, Protect and Manage. In part 2 we will dive into the first Dimension Use with determining workloads.
Raise Your SDS IQ (1 of 6): Practical Review of Scale-up Vendor-Defined “SDS”
10 May 2016 by Nexenta
by Michael Letschin, Field CTO
This is the first of six posts (aside from the Introduction) where we’re going to cover some practical details that help raise your SDS IQ and enable you to select the SDS solution that will deliver Storage on Your Terms. The first SDS flavor in our series is Scale-up Vendor-Defined “SDS”.
Scale-up Vendor-Defined “SDS” is where most of the traditional “big box” vendor solutions lie – think EMC’s VNX, NetApp’s FAS, or IBM DS4000 Series – each one being one or two usually commodity head nodes with JBOD behind it. While sold as an appliance, the argument is that SDS comes into play as front-end software that delivers REST-based management with rich APIs, to enable easy, automatic provisioning and management of storage.
Companies choose scale-up vendor-defined “SDS” often because it’s a well recognized brand, they have the vendor in-house already, and it appears to bring SDS benefits while maintaining a familiar in-house infrastructure. Scale-up Vendor-Defined “SDS” is often selected for legacy applications and some virtual apps, largely because its performance in these use cases is excellent. It’s a great choice if you’re running virtual machines with NFS, Exchange, or MS SQL. But, it’s still vendor-defined and not true SDS, so your hardware choices, and your flexibility, are restricted. It also means giving up one of the core SDS benefits – cost effectiveness – because you’ll be paying a premium for proprietary hardware. And that hardware is generally only one or two head nodes, so scalability is limited too.
Overall grade: D+
See below for a typical build and the report card: 
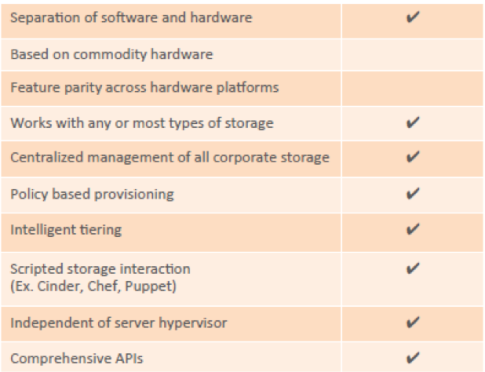
Watch this space for the next review in our series – Scale-up, Software-Only SDS
Is 2016 the year of the software-defined data center?
07 May 2016 by Nexenta
Even with my 20 years of experience working in technology, I am just a baby compared to some people I have encountered along the way.
Still, I sometimes think about the “old days” in IT. It was a time when data centers were dominated by mainframe systems and midrange monoliths like the AS/400. A time when virtualization was something done only on these big systems, and the only need for an x86 system was under your desk to access a mainframe when you didn’t have a classic thin client.
When my career in IT really began, I was working with systems like Windows NT and Exchange 5.5, and we were creating Web pages with this mysterious language called HTML that magically made things appear. Even in those days, there was this thought that there was no need for companies to be beholden to the largest vendors.
There was a notion/belief in the early 2000s that with the growth of VMware, eventually the data center would become a blend of multiple vendors and companies would be able to take back their own infrastructure, enabling them to control the way they supported their business. This transition marked the evolution from the traditional data center to the commodity-based data center, driven by business needs and created using software, rather than the monolith systems that big vendors charged exorbitant amounts for.
Fast-forward to 2016
Are we there yet? Not quite, but this could be the year. Most enterprises have nearly 90% of their systems virtualized on VMware, Xen or KVM and are managed by newer solutions like OpenStack. 2016 could finally be the year we see the commodity-based data center become reality.
To make this happen, there are so many components that need to be in the right place. We need to see x86 servers with enough power to support large database systems — check. We need the ability to choose between multiple vendors that all produce a similar-quality product, but differentiate themselves with their support and supply chain — check. We need to have networks that can handle multiple systems and the communication between them, without losing packets and without being based on a single large infrastructure — check. (Well, sorta . . . we will get to that one in a few.) Finally, we need software to drive all these systems and define the solutions, whether it is storage, compute or even networking.
We are just about there and are seeing an influx of companies that can provide these services, but can they unseat the incumbent large, publicly traded vendors that look to buy up all the small fish? That just may be the key to 2016 being the year of change for the data center we have all dreamed about since we walked away from worrying about what happens when the clock strikes midnight for the new millennium.
Over the next couple of blogs I will take a look at each of the categories and see if we are really as close as we think to 2016 being “The Year,” starting with the server and compute side.

IT Infrastructure Breaking Down? It’s Time for ChatOps…
ChatOps helps bridge the tasks of reporting and communications for faster, better-informed incident management
Won the battle and the war
There is little doubt that the data center is now dominated by x86 server hardware. The hardware can run with multiple CPU manufacturers, and has more cores than we could imagine in the ’90s and memory levels that exceed what helped put a man on the moon. All of this hardware is going to support everything from the large single applications to scale out big data apps that let us analyze every picture that was posted on Instagram or Facebook about kittens in the last 24 hours.
Let the vendors compete for you
Most users probably have their preference now in server vendors, and it is all about the extras these companies provide. It is not about the components within the servers. Most network cards are from one or two companies, and most processors are from one of two companies — you may have hard drives from multiple firms, but overall it’s just different-shaped, bent metal with a different label on the front.
The true differentiator for vendor choice comes in the form of supply chain and parts availability. The supply chain has begun to collapse around fewer global vendors, making it easier to price match between them. If you are only looking for regional or local support, that too has limited choice, and all the vendors know it. The choice is now truly in the hands of the consumer and, if planned out, can result in a race to the bottom on price, along with increased “hand-holding” when the equipment arrives.
GleSYS’ joint NexentaStor/InfiniFlash system deployment to be focus of upcoming webinar
04 May 2016 by Nexenta
In April, we announced that GleSYS Internet Services AB (GleSYS), a next-generation cloud platform provider based in Sweden, had deployed ours and SanDisk’s joint All Flash Software-Defined Storage Solution. The NexentaStor/InfiniFlash solution delivers cost effective, high performance storage architecture, empowering GleSYS and its customers to quickly scale capacity as required.
Providing hosted internet solutions to nearly 3,500 customers around the world, GleSYS specializes in offering its public cloud services to small- and medium-sized businesses on a self-serve basis. Prior to selecting the joint solution, the company was struggling to ensure the reliability of its storage solutions for customers, many of whom require extra performance provisioning instantly. However, GleSYS now has access to flexible and reliable storage architecture and, with unparalleled and limitless scalability to boot, the company has a tool that can support its impressive year-on-year growth predictions.
The deployment has been a huge success with GleSYS able to provide powerful and reliable cloud architectures to its increasing customer base. The solution has provided the company with numerous technical benefits, including:
- The new architecture runs at a constant 20k Input/Output Operations per Second (IOPS), with a latency of less than 1.5ms in its daily operations. The previous solution was only able to reach a maximum of 12k IOPS
- While IOPS currently peak at around 80k, GleSYS believes this is not the limit of the solution, but rather the max utilization that it has seen from its current hardware
- In regards to data center footprint, GleSYS has a 64TB hybrid storage solution allocating 16U. The joint solution can hold up to 512TB in only 7U
The GleSYS success story will be discussed in more detail during an upcoming webinar, May 11th 2016, 7am PT. Executives from GleSYS, Nexenta, SanDisk and Layer 8 will take a deep dive into the challenges that the organization was facing with its legacy storage set-ups, and how the NexentaStor/InfiniFlash system is ensuring better storage performance and reliability for the company and its customers. Register for the webinar here: https://www.brighttalk.com/webcast/12587/198547
For more information on the GleSYS deployment, the full case study can be viewed here (English) or here (Swedish).